/*Java Program to implement a queue in an employee structure.*/
import java.util.LinkedList;
class GenQueue { private LinkedList list = new LinkedList(); public void enqueue(E item) { list.addLast(item); } public E dequeue() { return list.poll(); } public boolean hasItems() { return !list.isEmpty(); } public int size() { return list.size(); } public void addItems(GenQueue q) { while (q.hasItems()) list.addLast(q.dequeue()); } }
public class GenQueueTest { public static void main(String[] args) { GenQueue empList; empList = new GenQueue(); GenQueue hList; hList = new GenQueue(); hList.enqueue(new HourlyEmployee("T", "D")); hList.enqueue(new HourlyEmployee("G", "B")); hList.enqueue(new HourlyEmployee("F", "S")); empList.addItems(hList); System.out.println("The employees' names are:"); while (empList.hasItems()) { Employee emp = empList.dequeue(); System.out.println(emp.firstName + " " + emp.lastName); } } }
class Employee { public String lastName; public String firstName; public Employee() { } public Employee(String last, String first) { this.lastName = last; this.firstName = first; } public String toString() { return firstName + " " + lastName; } }
class HourlyEmployee extends Employee { public double hourlyRate; public HourlyEmployee(String last, String first) { super(last, first); } }
This example shows the way of using method for calculating Fibonacci Series upto n numbers.
public class MainClass { public static long fibonacci(long number) { if ((number == 0) || (number == 1)) return number; else return fibonacci(number - 1) + fibonacci(number - 2); } public static void main(String[] args) { for (int counter = 0; counter
Output
Fibonacci of 0 is: 0 Fibonacci of 1 is: 1 Fibonacci of 2 is: 1 Fibonacci of 3 is: 2 Fibonacci of 4 is: 3 Fibonacci of 5 is: 5 Fibonacci of 6 is: 8 Fibonacci of 7 is: 13 Fibonacci of 8 is: 21 Fibonacci of 9 is: 34 Fibonacci of 10 is: 55
Capability maturity model and testing maturity model
How many Effort Estimation methods available in market for Testing?
A Effort estimation consists in predict how many hours of work and how many workers are needed to develop a project. The effort invested in a software project is probably one of the most important and most analysed variables in recent years in the process of project management. The determination of the value of this variable when initiating software projects allows us to plan adequately any forthcoming activities. As far as estimation and prediction is concerned there is still a number of unsolved problems and errors. To obtain good results it is essential to take into consideration any previous projects. Estimating the effort with a high grade of reliability is a problem which has not yet been solved and even the project manager has to deal with it since the beginning.
What are the different Methodologies in Agile Development Model?
There are currently seven different Agile methodologies that I am aware of:
Extreme Programming (XP)
Scrum
Lean Software Development
Feature-Driven Development
Agile Unified Process
Crystal
Dynamic Systems Development Model (DSDM)
How the 2 wings and body of the Butterfly Model of Test Development is Represented?
The Butterfly Model focuses on verification and validation of software products and is therefore a good fit for software testing tasks that are incorporated into the V-model of software development. This model provides a graphic picture of the complexity of test tasks using the outline of a butterfly. The areas occupied by the wings and body are approximately related to the level of effort afforded to each of the activities included in the model. In addition to this the reference of the butterfly stems from Chaos theory which states that a small disturbance in part of a system can have huge consequences in some other part of the system. The development of a software system has certain similarities. Small modifications or errors in code may result in significant degradations in an application’s performance. The model establishes three general areas of test activities that are illustrated by the butterfly’s graphic outline. They are:
Test Analysis (butterfly’s left wing)
Test Design (right wing)
Test Execution (butterfly’s body)
What does the mclabe cyclomatic complexity of a program determine?
Cyclomatic complexity is likely the most widely used complexity metric in software engineering. It describes the complexity of a procedure by measuring the linearly independent paths through its source code. .
How do you obtain the expected results for testing a search operation?
Corresponding Search Window should be opened & hold corresponding field names in that.
Search Operation should be shown correct result while valid data.
Search Operation should be shown warning message while enter invalid data.
Search Operation should be shown output for all the condition in valid inputs.
Describe to the basic elements you put in a defect report?
project name
module name
defect detected on
defect detected by
defect id
defect name
snapshort of the defect(if the defect is in the non reproducible environment)
priority,severity,status
defect resolved by
defect resolved on.
What is Impact analysis? As a tester how will you do impact analysis in your project?
Suppose after completion of an application or module, if another module is to be added, then we need to test the new module as well as the impacted area which is affected by adding a new module.
Impact Analysis will be done to find the impact area of the application by adding a new module. Generally team lead will take the initiate for this.
Team lead will send a mail to client asking for the impact area (if developer is new to domain), also send a mail to development team and testing team asking for the impacted area. After getting the response of all three, team lead will do the consolidated report of all the mails. This consolidated mail will be given to the Test Engineer saying this is the Impact Analysis Report and these are the impact areas.
What is the main Goal of Defect Prevention meeting?
Closed defects can be reopened due to some of the following reason:
Fix given for some other issue may reopen closed defects.
Deployment not properly done at the time of fixing new defects.
Build issue.
And hence to prevent such defects to reopen, regression testing should be performed on the main flow, scenarios before each testing phase is completed.
And also if time permits quick sanity testing could be carried out to ensure that there is no impact to the application or system before moving on to the next testing phase.
What are the factors affecting a manual testing project and what are the ways to overcome it?
Go for Manual Testing in the following cases: Unstable Software. To explore New Software. No Automation suite available. Adhoc testing (unplanned test cases). Not critical project & only one time testing & the effort required is less than the effort required for automation.
Go for Automation in the following cases: Stable Software. Any application with a High degree of risk associated with the failure is a good candidate for test automation. (Aircrafts, Patient monitor,) Testing needs to be repeated.
Advantages of Automation: Accelerate releases (reduces regression effort) With repeatable tests ensure consistency across multiple supported platforms Greater Application Coverage. Can test more often & more completely Convenient test reports for analysis
How do you verify the test results and How do you proceed when you do not get the expected results?
We need to check whether Expected Result coresponding to Test case mentioned in Test Case Document is same as Actual Result.If they are same then Test Case passes and if they are not same then we have to see what is different and why it different. After narrowing down we need to raise a defect and map that defect to a Test case.
In real time how you do the Soak Testing?
Soak Testing: Running a system at high load for a prolonged period of time. For example, running several times more transactions in an entire day (or night) than would be expected in a busy day, to identify and performance problems that appear
What do you mean by Trend Analysis?
In project management trend analysis is a mathematical technique that uses historical results to predict future outcome. This is achieved by tracking variances in cost and schedule performance. In this context it is a project management quality control tool.
What is the difference between interoperability and compatibility testing with some examples?
Interoperatability:-To check if the software can co exist with other supporting softwares in the system
Compatibility:-To check if the software runs on different types of operating systems according to customer requirements.
What is ‘fish pond analysis’ w.r.t software testing?
This is one of the SDLC process generally we are following. Its like in fish model that’s why it got the name like that.
What does a manual tester need to become proficient with DB Testing?
Need knowledge of SQL query
What is difference between Validation and Verification?
Verification is the process of confirming that s/w “meets its specification”.It involves reviews and meetings to evaluate documents,plans,code,requirement and specification.This can be done with checklist,issues lists and walkthroughs.It is the examination of the process and checks r we building the product right Validation is the process of confirming that it “meets the user’s requirements”.Validation typically involves actual testing and take place after verification.
What is difference between Known regression Testing and Unknown Regression testing?
Regression testing means it is the type of testing in which one will conduct testing on an already tested functionality again and again. Regression testing will be conducted in two situations.
If the test engineer find any defect on one functionality then after the rectification of that defect from the development department again testing on that defected functionality and retesting the related functionalities of that defected functionality.
If the new features are added to that application testing on that new feature functionality and also the related functionality of that new features to be tested.
What is Quality Matrix in Software Testing?
By word quality we may be more generalized towards our target. but being a quality continuous a “quality matrix” should have;
logical parameterization of our parameters i.e. first we should confirm that is parameter “a” has logical connection with parameter “b”
Matrix should be result oriented. we can extract/deduce some logical results from each matrix
Every matrix should be complete in its domain it should not further dependent on other parameters other than selected
Every matrix should work in boundaries of your requirements
A software process is a series of steps used to solve a problem. The following figure shows a pictorial view of how an organization has defined a way to solve risk problems. In the diagram we have shown two branches: one is the process and the second branch shows a sample risk mitigation process for an organization. For instance, the risk mitigation process defines what step any department should follow to mitigate a risk. The process is as follows:
Identify the risk of the project by discussion, proper requirement gathering, and forecasting.
Once you have identified the risk prioritize which risk has the most impact and should be tackled on a priority basis.
Analyze how the risk can be solved by proper impact analysis and planning.
Finally, using the above analysis, we mitigate the risk.
What are the different cost elements involved in implementing a process in an organization?
Below are some of the cost elements involved in the implementing process:
Salary: This forms the major component of implementing any process, the salary of the employees. Normally while implementing a process in a company either organization can recruit full-time people or they can share resources part-time for implementing the process.
Consultant: If the process is new it can also involve consultants which are again an added cost.
Training Costs: Employees of the company may also have to undergo training in order to implement the new process
Tools: In order to implement the process an organization will also need to buy tools which again need to be budgeted for.
What is a maturity level?
A maturity level specifies the level of performance expected from an organization.
What is a model?
A model is nothing but best practices followed in an industry to solve issues and problems. Models are not made in a day but are finalized and realized by years of experience and continuous improvements.
Many companies reinvent the wheel rather than following time tested models in the industry.
Can you explain process areas in CMMI?
A process area is the area of improvement defined by CMMI. Every maturity level consists of process areas. A process area is a group of practices or activities performed collectively to achieve a specific objective. For instance, you can see from the following figure we have process areas such as project planning, configuration management, and requirement gathering.
Can you explain tailoring?
As the name suggests, tailoring is nothing but changing an action to achieve an objective according to conditions. Whenever tailoring is done there should be adequate reasons for it. Remember when a process is defined in an organization it should be followed properly. So even if tailoring is applied the process is not bypassed or omitted.
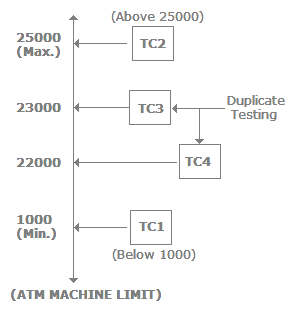
In some projects there are scenarios where we need to do boundary value testing. For instance, let’s say for a bank application you can withdraw a maximum of 25000 and a minimum of 100. So in boundary value testing we only test the exact boundaries rather than hitting in the middle. That means we only test above the max and below the max. This covers all scenarios. The following figure shows the boundary value testing for the bank application which we just described. TC1 and TC2 are sufficient to test all conditions for the bank. TC3 and TC4 are just duplicate/redundant test cases which really do not add any value to the testing. So by applying proper boundary value fundamentals we can avoid duplicate test cases, which do not add value to the testing.
Can you explain equivalence partitioning?
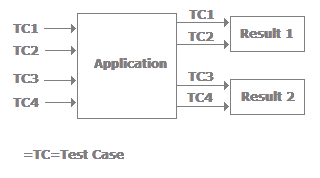
In equivalence partitioning we identify inputs which are treated by the system in the same way and produce the same results. You can see from the following figure applications TC1 and TC2 give the same results (i.e., TC3 and TC4 both give the same result, Result2). In short, we have two redundant test cases. By applying equivalence partitioning we minimize the redundant test cases.
So apply the test below to see if it forms an equivalence class or not:
All the test cases should test the same thing.
They should produce the same results.
If one test case catches a bug, then the other should also catch it.
If one of them does not catch the defect, then the other should not catch it.
Can you explain random/monkey testing?
Random testing is sometimes called monkey testing. In Random testing, data is generated randomly often using a tool. For instance, the following figure shows how randomly-generated data is sent to the system. This data is generated either using a tool or some automated mechanism. With this randomly generated input the system is then tested and results are observed accordingly.
Random testing has the following weakness:
They are not realistic.
Many of the tests are redundant and unrealistic.
You will spend more time analyzing results.
You cannot recreate the test if you do not record what data was used for testing.
This kind of testing is really of no use and is normally performed by newcomers. Its best use is to see if the system will hold up under adverse effects.
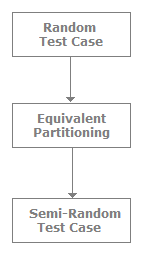
What are semi-random test cases?
As the name specifies semi-random testing is nothing but controlling random testing and removing redundant test cases. So what we do is perform random test cases and equivalence partitioning to those test cases, which in turn removes redundant test cases, thus giving us semi-random test cases.
Can you explain a pair-wise defect?
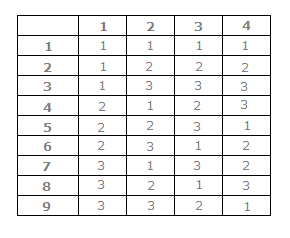
Orthogonal array is a two-dimensional array in which if we choose any two columns in the array and all the combinations of numbers will appear in those columns. The following figure shows a simple L9(34) orthogonal array. In this the number 9 indicates that it has 9 rows. The number 4 indicates that it has 4 columns and 3 indicates that each cell contains a 1, 2, and 3. Choose any two columns. Let’s choose column 1 and 2. It has (1,1), (1,2), (1,3), (2,1), (2,2), (2,3), (3,1), (3,2), (3,3) combination values. As you can see these values cover all the values in the array. Compare the values with the combination of column 3 and 4 and they will fall in some pair. This is applied in software testing which helps us eliminate duplicate test cases.
What is negative and positive testing?
A negative test is when you put in an invalid input and receive errors.
A positive test is when you put in a valid input and expect some action to be completed in accordance with the specification.
How did you define severity ratings in your project?
There are four types of severity ratings as shown in the table:
Severity 1 (showstoppers): These kinds of defects do not allow the application to move ahead. So they are also called showstopper defects.
Severity 2 (application continues with severe defects): Application continues working with these types of defects, but they can have high implications, later, which can be more difficult to remove.
Severity 3 (application continues with unexpected results): In this scenario the application continues but with unexpected results.
Severity 4 (suggestions): Defects with these severities are suggestions given by the customer to make the application better. These kinds of defects have the least priority and are considered at the end of the project or during the maintenance stage of the project.
Can you explain exploratory testing?
Exploratory testing is also called adhoc testing, but in reality it’s not completely adhoc. Ad hoc testing is an unplanned, unstructured, may be even an impulsive journey through the system with the intent of finding bugs. Exploratory testing is simultaneous learning, test design, and test execution. In other words, exploratory testing is any testing done to the extent that the tester proactively controls the design of the tests as those tests are performed and uses information gained while testing to design better tests. Exploratory testers are not merely keying in random data, but rather testing areas that their experience (or imagination) tells them are important and then going where those tests take them.
Can you explain decision tables?
As the name suggests they are tables that list all possible inputs and all possible outputs. A general form of decision table is shown in the following figure.
Condition 1 through Condition N indicates various input conditions. Action 1 through Condition N are actions that should be taken depending on various input combinations. Each rule defines unique combinations of conditions that result in actions associated with that rule.
What are the different Ways of doing Black Box testing?
There are five methodologies most frequently used:
Top down according to budget
WBS (Work Breakdown Structure)
Guess and gut feeling
Early project data
TPA (Test Point Analysis)
Can you explain TPA analysis?
TPA is a technique used to estimate test efforts for black box testing. Inputs for TPA are the counts derived from function points.
Below are the features of TPA:
Used to estimate only black box testing.
Require function points as inputs.
Can you explain the elementary process?
Software applications are a combination of elementary processes. When elementary processes come together they form a software application.
There are two types of elementary processes:
Dynamic elementary Process: The dynamic elementary process moves data from an internal application boundary to an external application boundary or vice-versa. Example: Input data screen where a user inputs data into the application. Data moves from the input screen inside the application.
Static elementary Process: Static elementary process which maintains the data of the application either inside the application boundary or in the external application boundary. For example, in a customer maintenance screen maintaining customer data is a static elementary process.
How do you estimate white box testing?
The testing estimates derived from function points are actually the estimates for white box testing. So in the following figure the man days are actually the estimates for white box testing of the project. It does not take into account black box testing estimation.
Can you explain the various elements of function points FTR, ILF, EIF, EI, EO, EQ, and GSC?
File Type References (FTRs): An FTR is a file or data referenced by a transaction. An FTR should be an ILF or EIF. So count each ILF or EIF read during the process. If the EP is maintained as an ILF then count that as an FTR. So by default you will always have one FTR in any EP.
Internal Logical Files (ILFs): ILFs are logically related data from a user’s point of view. They reside in the internal application boundary and are maintained through the elementary process of the application.ILFs can have a maintenance screen but not always.
External Interface Files (EIFs): EIFs reside in the external application boundary. EIFs are used only for reference purposes and are not maintained by internal applications. EIFs are maintained by external applications.
External Input (EI): EIs are dynamic elementary processes in which data is received from the external application boundary. Example: User interaction screens, when data comes from the User Interface to the Internal Application.
External Output (EO): EOs are dynamic elementary processes in which derived data crosses from the internal application boundary to the external application boundary.
External Inquiry (EQ): An EQ is a dynamic elementary process in which result data is retrieved from one or more ILF or EIF. In this EP some input requests have to enter the application boundary. Output results exits the application boundary.
General System Characteristics (GSCs): This section is the most important section. All the previously discussed sections relate only to applications. But there are other things also to be considered while making software, such as are you going to make it an N-Tier application, what’s the performance level the user is expecting, etc. These other factors are called GSCs.
Can you explain an Application boundary?
The first step in FPA is to define the boundary. There are two types of major boundaries:
Internal Application Boundary
External Application Boundary
The external application boundary can be identified using the following litmus test:
Does it have or will it have any other interface to maintain its data, which was not developed by you?.
Does your program have to go through a third party API or layer? In order for your application to interact with the tax department application your code has to interact with the tax department API.
The best litmus test is to ask yourself if you have full access to the system. If you have full rights to make changes then it is an internal application boundary, otherwise it is an external application boundary.
Can you explain how TPA works?
There are three main elements which determine estimates for black box testing: size, test strategy, and productivity. Using all three elements we can determine the estimate for black box testing for a given project. Let’s take a look at these elements.
Size: The most important aspect of estimating is definitely the size of the project. The size of a project is mainly defined by the number of function points. But a function point fails or pays the least attention to the following factors:
Complexity: Complexity defines how many conditions exist in function points identified during a project. More conditions means more test cases which means more testing estimates.
Interfacing: How much does one function affect the other part of the system? If a function is modified then accordingly the other systems have to be tested as one function always impacts another.
Uniformity: How reusable is the application? It is important to consider how many similar structured functions exist in the system. It is important to consider the extent to which the system allows testing with slight modifications.
Test strategy: Every project has certain requirements. The importance of all these requirements also affects testing estimates. Any requirement importance is from two perspectives: one is the user importance and the other is the user usage. Depending on these two characteristics a requirement rating can be generated and a strategy can be chalked out accordingly, which also means that estimates vary accordingly.
Productivity: This is one more important aspect to be considered while estimating black box testing. Productivity depends on many aspects.
Can you explain steps in function points?
Below are the steps in function points:
First Count ILF, EIF, EI, EQ, RET, DET, FTR and use the rating tables. After you have counted all the elements you will get the unadjusted function points.
Put rating values 0 to 5 to all 14 GSC. Adding total of all 14 GSC to come out with total VAF. Formula for VAF = 0.65 + (sum of all GSC factor/100).
Finally, make the calculation of adjusted function point. Formula: Total function point = VAF * Unadjusted function point.
Make estimation how many function points you will do per day. This is also called as “Performance factor”.On basis of performance factor, you can calculate Man/Days.
Can you explain function points?
Function points are a unit measure for software much like an hour is to measuring time, miles are to measuring distance or Celsius is to measuring temperature. Function Points are an ordinal measure much like other measures such as kilometers, Fahrenheit, hours, so on and so forth.
This approach computes the total function points (FP) value for the project, by totaling the number of external user inputs, inquiries, outputs, and master files, and then applying the following weights: inputs (4), outputs (5), inquiries (4), and master files (10). Each FP contributor can be adjusted within a range of +/-35% for a specific project complexity.
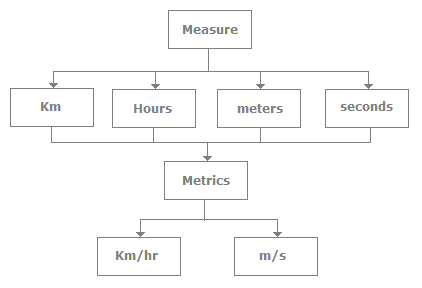
Measures are quantitatively unit defined elements, for instance, hours, km, etc. Metrics are basically comprised of more than one measure. For instance, we can have metrics such as km/hr, m/s etc.
Can you explain how the number of defects is measured?
The number of defects is one of the measures used to measure test effectiveness. One of the side effects of the number of defects is that all bugs are not equal. So it becomes necessary to weight bugs according to their criticality level. If we are using the number of defects as the metric measurement the following are the issues:
The number of bugs that originally existed significantly impacts the number of bugs discovered, which in turns gives a wrong measure of the software quality.
All defects are not equal so defects should be numbered with a criticality level to get the right software quality measure.
Can you explain unit and system test DRE?
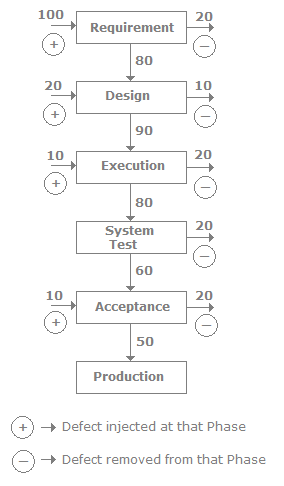
DRE is also useful to measure the effectiveness of a particular test such as acceptance, unit, or system testing. The following figure shows defect numbers at various software cycle levels. The 1 indicates that defects are input at the phase and2indicates that these many defects were removed from that particular phase. For instance, in the requirement phase 100 defects were present, but 20 defects are removed from the requirement phase due to a code review. So if 20 defects are removed then 80 defects get carried to the new phase (design) and so on.
Can you explain DRE?
DRE (Defect Removal Efficiency) is a powerful metric used to measure test effectiveness. From this metric we come to know how many bugs we found from the set of bugs which we could have found. The following is the formula for calculating DRE. We need two inputs for calculating this metric: the number of bugs found during development and the number of defects detected at the end user.
But the success of DRE depends on several factors. The following are some of them:
Severity and distribution of bugs must be taken into account.
Second, how do we confirm when the customer has found all the bugs. This is normally achieved by looking at the history of the customer.
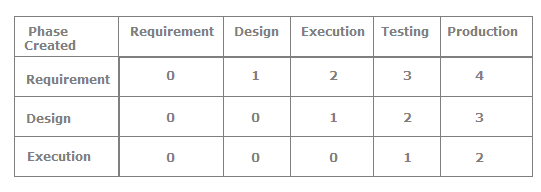
Can you explain defect age and defect spoilage?
Defect age is also called a phase age or phage. One of the most important things to remember in testing is that the later we find a defect the more it costs to fix it. Defect age and defect spoilage metrics work with the same fundamental, i.e., how late you found the defect. So the first thing we need to define is what is the scale of the defect age according to phases. For instance, the following table defines the scale according to phases. So, for instance, requirement defects, if found in the design phase, have a scale of 1, and the same defect, if propagated until the production phase, goes up to a scale of 4.
Once the scale is decided now we can find the defect spoilage. Defect spoilage is defects from the previous phase multiplied by the scale. For instance, in the following figure we have found 8 defects in the design phase from which 4 defects are propagated from the requirement phase. So we multiply the 4 defects with the scale defined in the previous table, so we get the value of 4. In the same fashion we calculate for all the phases. The following is the spoilage formula.
Can you explain how the number of production defects is measured?
This is one of the most effective measures. The number of defects found in a production is recorded. The only issue with this measure is it can have latent and masked defects which can give us the wrong value regarding software quality.
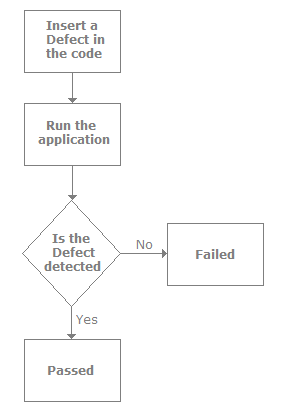
Can you explain defect seeding?
Defect seeding is a technique that was developed to estimate the number of defects resident in a piece of software. It’s an offline technique and should not be used by everyone. The process is the following: we inject the application with defects and then see if the defect is found or not. So, for instance, if we have injected 100 defects we try to get three values. First how many seeded defects were discovered, how many were not discovered, and how many new defects (unseeded) are discovered. By using defect seeding we can predict the number of defects remaining in the system.
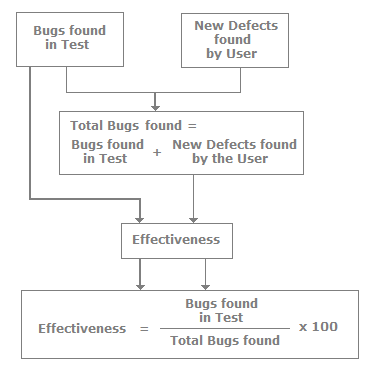
How do you measure test effectiveness?
Test effectiveness is the measure of the bug-finding ability of our tests. In short, it measures how good the tests were. So effectiveness is the ratio of the measure of bugs found during testing to the total bugs found. Total bugs are the sum of new defects found by the user plus the bugs found in the test. The following figure explains the calculations in a pictorial format.